
Sponsored Links
データの読み込みと準備
サンプルデータは、「2-3d 因子分析実例《セールスマンデータ)(2-3d.xls)」[1]を使わせていただきます。もともと因子分析の練習をするためのデータで、セールスマンに対する評価項目がたくさん掲載されていて、多分それぞれ10段階順序尺で評価されています。ここでは、容姿の評価が高・低の2群に分けて、好感度の評価に差があるかどうかを検定してみます。
R Console
[1] 松原望の総合案内サイト – 2-3d セールスマン・データの因子分析
> x <- read.table(pipe("pbpaste"), header=TRUE) # クリップボードからデータを読み込み、xに代入。ちなみにこちらはMac用のコードでWindowsは、read.table("clipboard", header=TRUE)。
> str(x) # xの構造を確認。
'data.frame': 48 obs. of 2 variables:
$ youshi : int 7 10 8 6 8 7 9 9 9 7 ...
$ koukando: int 5 8 6 5 8 6 8 8 8 2 ...
> quantile(x$youshi) # 容姿の四分位数を確認。7が中央値なので、中央値は除いて、7未満を容姿低群、7より上を容姿高群と設定することにする。
0% 25% 50% 75% 100%
3.00 6.00 7.00 8.25 10.00
> low <- subset(x, youshi<7) # 容姿7未満をlowに代入。
> high <- subset(x, youshi>7) # 容姿7より上をhighに代入。
> quantile(low$koukando) # low群における好感度の四分位数を計算。
0% 25% 50% 75% 100%
0.00 3.25 6.50 7.75 10.00
> quantile(high$koukando) # high群における好感度の四分位数を計算。
0% 25% 50% 75% 100%
4.0 7.0 8.0 8.5 10.0
ウィルコクソンの順位和検定を実行
対応ない2群の比較なので、ウィルコクソンの順位和検定を用います(対応のある場合は、ウィルコクソンの符号順位検定)。Rにはwilcox.testという関数が用意されていますが、この関数はデータにタイ(同じ値)があった時に正確な値を計算できないらしく、パッケージexactRankTestsをインストールして、正確検定を行うことができるwilcox.exactを用います。ただし、データ数が多いと正確検定はできないようです[1]。
R Console
> library(exactRankTests)> wilcox.exact(low$koukando, high$koukando, paired = FALSE) # ウィルコクソンの順位和検定の実行。対応のないのでpaired=FALSEを指定。
Exact Wilcoxon rank sum test
data: low$koukando and high$koukando
W = 101, p-value = 0.05698
alternative hypothesis: true mu is not equal to 0ギリギリ有意差がなくてホッとしました。
[1] データ科学便覧 – ウィルコクソンの順位和検定
効果量の計算
効果量の計算にはパッケージorddomを使います。たくさん結果が出ますが、その中のdeltaを参照します。Cliffの⊿という統計量らしいです。
R Console
> library(orddom) #パッケージorddomの読み込み。
> orddom(low$koukando, high$koukando, paired = FALSE) # 効果量の計算。対応のない検定の効果量を求めるので、paired=FALSEと指定。
ordinal metric
var1_X "group 1 (x)" "group 1 (x)"
var2_Y "group 2 (y)" "group 2 (y)"
type_title "indep" "indep"
n in X "14" "14"
n in Y "23" "23"
N #Y>X "205" "205"
N #Y=X "32" "32"
N #Y<X "85" "85" PS X>Y "0.263975155279503" "0.299304635505802"
PS Y>X "0.636645962732919" "0.700695364494198"
A X>Y "0.313664596273292" "0.313664596273292"
A Y>X "0.686335403726708" "0.686335403726708"
delta "0.372670807453416" "1.8944099378882"
1-alpha "95" "95"
CI low "-0.0654909361732113" "0.213652808150112"
CI high "0.690351499210486" "3.57516706762629"
s delta "0.20071491127763" "2.35636162472516"
var delta "0.0402864756091869" "5.55244010647737"
se delta NA "0.79875734998837"
z/t score "1.85671709730592" "2.37169640807159"
H1 tails p/CI "2" "2"
p "0.0717843557861564" "0.0543277188001214"
Cohen's d "0.58215416637435" "0.803955521092465"
d CI low "-0.0794990965637654" "0.114780184718098"
d CI high "1.43562571679683" "1.49313085746683"
var d.i "0.491119466544797" "10.0659340659341"
var dj. "0.134024360732435" "2.88537549407115"
var dij "0.764110601575047" "12.1445792457576"
df "35" "17.6153860360796"
NNT "2.68333333333333" "2.10102667292829" パッケージorddomに含まれている関数の内、以下のようにコマンドを打つとグラフィカルなデータを出してくれます。これは分かりやすい。[1]
R Console
> delta_gr(low$koukando, high$koukando, paired=FALSE)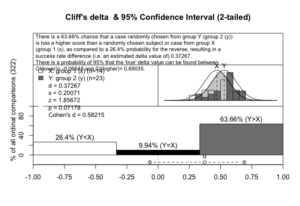

Sponsored Links
